2026世界杯赛事竞猜中国官网 李飞飞再脱手,空间智能的ImageNet来了

听雨 发自 凹非寺
量子位 | 公众号 QbitAI
ImageNet之后,李飞飞再脱手!
李飞飞团队最新发布ESI-Bench——一个有益用来评测具身空间智能的新基准。

往时的空间智能评测默许给模子最优不雅测,而ESI-Bench第一个把不雅察者变成行动者,闭合了感知-行动回路。
它为具身空间智能界限提供了一个系统性的评测框架,覆盖东谈主类中枢空间贯通本事的四大维度。
论文的中枢论断是:面前的AI看图很横暴,但离「会动、会摸、会主动找谜底」的空间智能还差得远。

ESI-Bench是什么
ESI-Bench发布的布景,是由于面前的空间智能benchmark,测的都是「被迫感知」。
把一张或几张图片扔给模子,问「A物体在B物体的左边仍是右边」「这个杯子能装若干水」「抽屉里有莫得东西」,这样的题目测出来的是模子的眼力,而非空间推理本事。
反不雅东谈主类是怎样作念的?东谈主类会站起来绕到物体背后去看,会把抽屉拉开,会把水倒出来量一量。
这即是ESI-Bench的中枢态度:把不雅察者变成行动者。

现实寰球里,智能体必须像东谈主类相通,主动决定行动、获取笔据,再基于新不雅测作念下一步判断。团队把它称为「感知-行动回路」(Perception-Action Loop)。
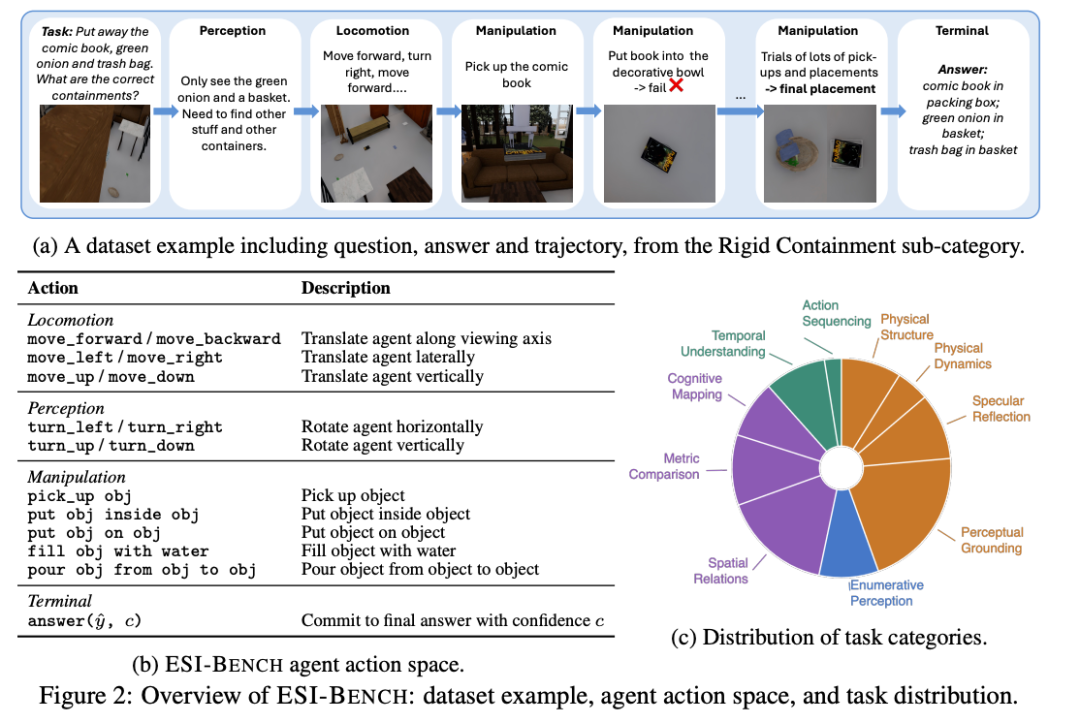
ESI-Bench即是这样一套越过现存基准的空间智能新评测基准,它包含10个任务类别,29个子类别,3081个任求实例,全部在OmniGibson仿真平台上构建,场景素材来自BEHAVIOR-1K场景库。

统共任务围绕Spelke的四大中枢学问系统瞎想,也即是东谈主类婴儿天生就具备的空间直观:物体表征、布局与几何、数目表征、方针导向行动。
它的关节设定在于行动强制。每一谈题,AI智能体必须主动行动本事拿到弥散信息作答。模子不可坐在原地等图片,它要决定往哪走、看什么、拿什么、怎样操作。

举几个具体的例子:
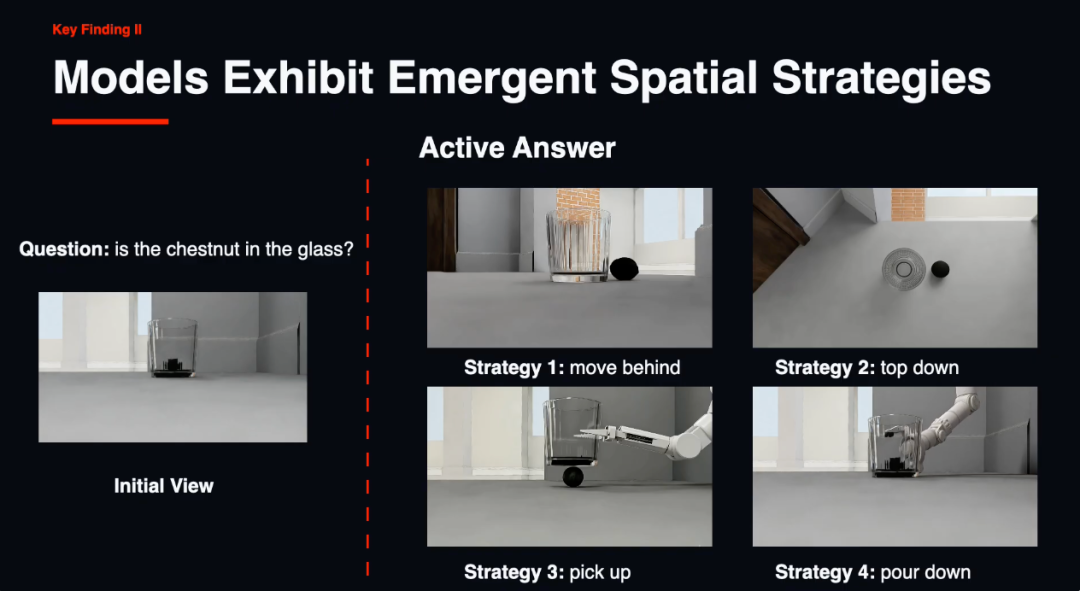
比如评测中有一谈「刚性容纳」题:给定几个容器和几个物体,要求把物体全部装进去。有的容器启齿小、有的里面有隔板、有的盖子需要通达本事看到真正容量。
模子必须走近、俯身、以致把容器提起来从底部不雅察,本事判断能不可装得下。
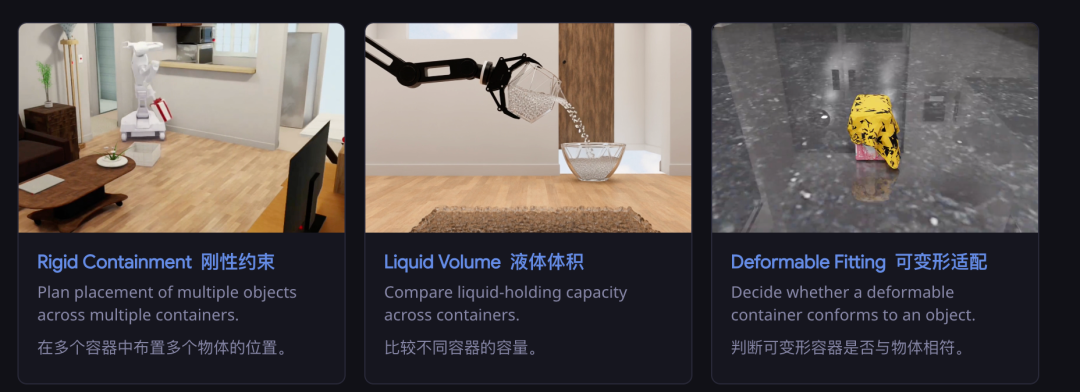
还有「液体体积」题:两个杯子,从外不雅看不出容量各异,模子需要把水倒进去测试,梗概径直提起来预计。
这样一说,群众应该也能直不雅感受到这套评测基准的瞎想理念:
正确谜底不在职何单张图片里,智能体必须主动行动并推理出正确效果。
团队相等指出,与此前责任比较,ESI-Bench在三个所在有所越过:
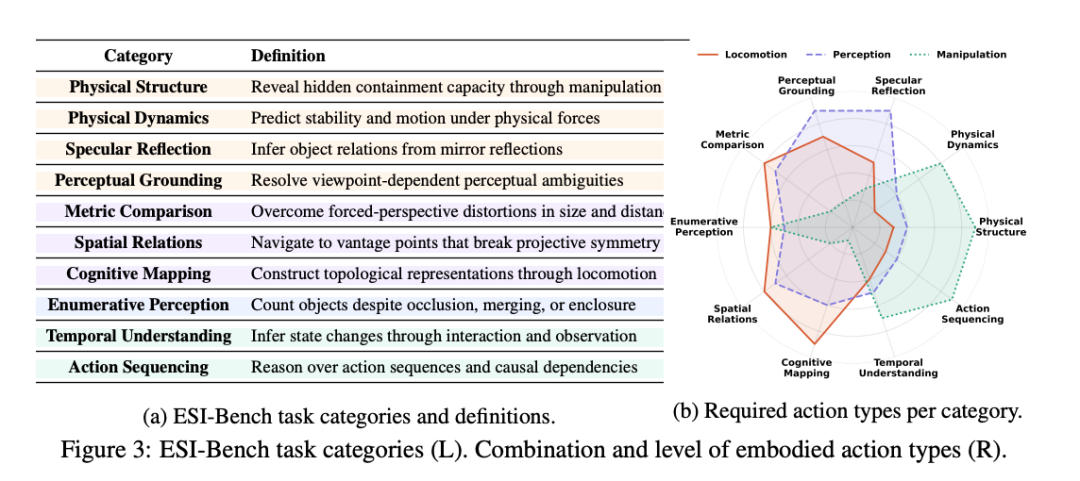
从空间感知到空间本事:在这里,智能体不仅根据他们能感知到什么来评估,还根据他们是否知谈部署哪些具体本事来料理空间任务来评估;
聘用性感知:智能体必须笃信哪些不雅察值得获取,优先斟酌与任务筹办的信息而不是冗余或无信息的输入;
料理感知歧义:智能体必须通过误导性不雅察进行推理,以推断覆盖的空间结构和越过径直不雅察的潜在物理阻挡。
测完发现了啥?3个中枢论断
团队拿现时最强的多模态大模子作念了全面测试,包括GPT-5和Gemini系列。
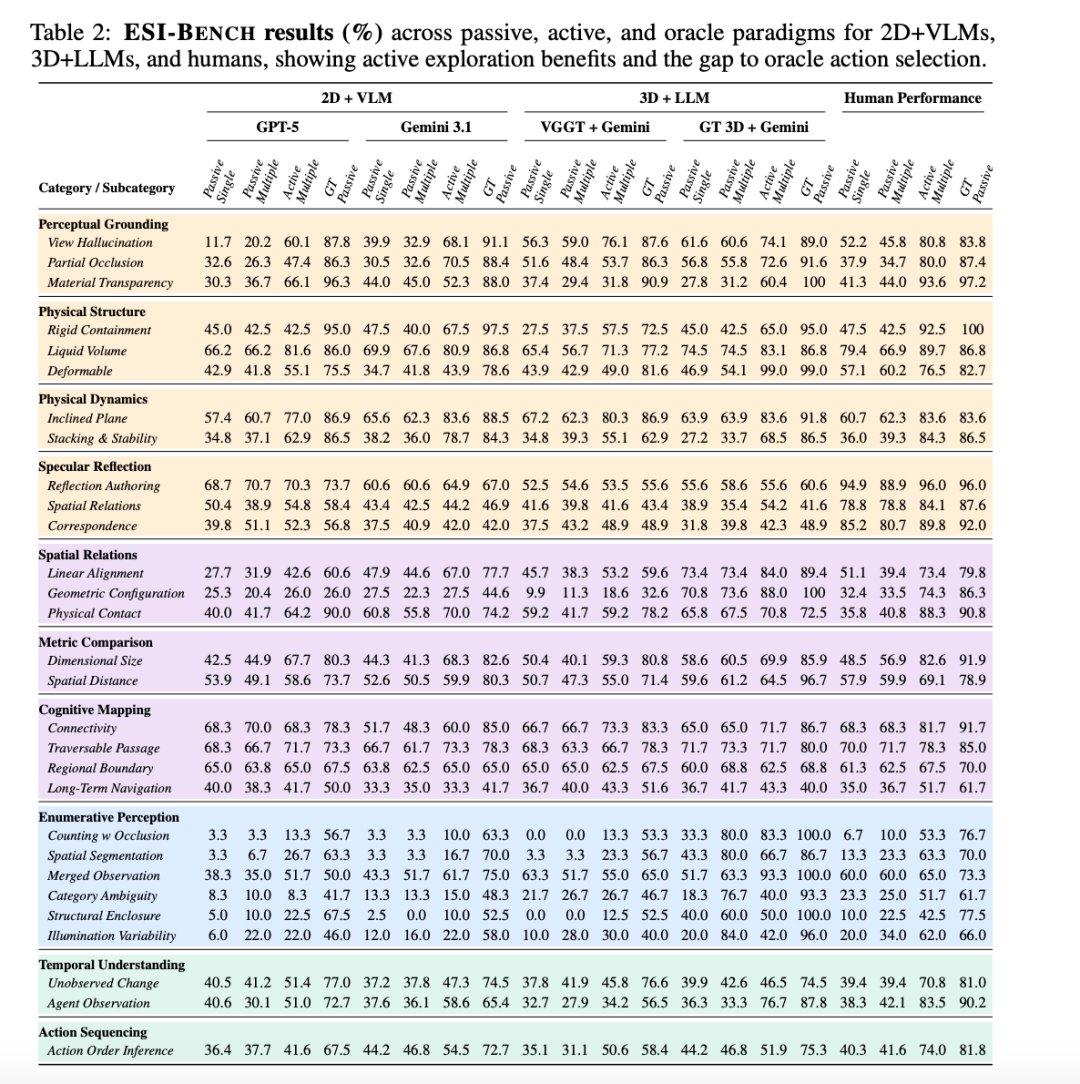
这是最主要的实验效果图,包含了ESI-Bench在被迫感知、主动探索、Oracle三种范式下的各项任务准确率,涵盖2D+VLM、3D+LLM及东谈主类基线。
中枢论断有3个。
第一,感知不是瓶颈,行动才是。
好音信是,主动探索确乎有用。在莫得很是提醒的情况下,开云体育中国官网在线入口智能体自愿走漏出多种空间政策。
比如绕到物体背后不雅察(move-behind)、切换鸟瞰角度(top-down)、把物体提起来(pick-up)、把水倒出来考据(pour-out)。
Gemini 3.1在「部分掩饰」任务上,淌若给到最好不雅察视角,准确率从14.6%暴涨到95.1%。
这讲明,模子自己的感知本事是好的,只须给对视角,它就能看得懂。
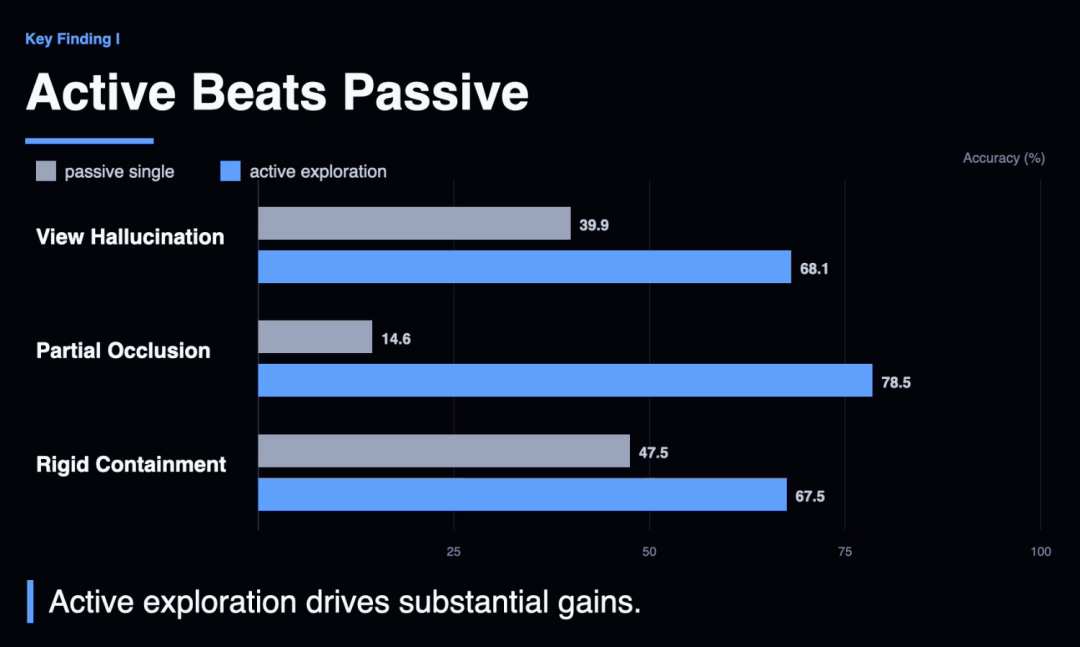
但问题在于,模子我方找不到阿谁对的视角。
更灾祸的问题在于,被迫多视角政策不仅没用,反而无益。
让GPT-5多看几张当场角度的图片,空间距离任务的准确率从53.9%降到49.1%。图看得多了,分反而低了。
 △
△
GPT-5和Gemini 3.1在主动探索中达到正确谜底所需的平均步数
团队把这个表象定名为「算作盲视」(Action Blindness),一个差算作导致一个差视角,差视角触发更差算作,酿成不可逆的级联失败。
在结构围合任务上,主动探索政策和天主视角的差距高达49.7%。

也即是说,空间智能的卡点不在于视觉模子不够强,而是行动政策确实为零。
第二,3D重建不是全能药,不齐备的3D比2D更坑。
既然2D被迫看图不行,那上3D呢?这亦然现时好多具身智能团队的门路,先重建三维场景,2026世界杯赛事竞猜最新版V2026.FIFA再在场景图上作念推理。
效果发现,淌若给的是真值3D(天主视角的齐备几何),那确乎很强。
Gemini在材质透明任务上,2D版块得分44.0%,3D版块得分60.4%,培育16.4个百分点。在需要精准深度信息的任务上,3D grounding有自然上风。
但淌若是真正重建呢?团队用现时起初进的VGGT模子作念场景重建,再把重建效果喂给推理模子。
效果那叫一个惨不忍闻:几何建设任务上,2D基线得分27.5%,VGGT重建后的场景图得分只须9.9%。

这讲明,不齐备的3D不是中性失败,它是负向失败。几何伪影、掩饰补全失误、深度揣度偏差,把这些失真信息编码成场景图,就等于给推理模子喂了一份「有毒」的输入。
比较之下,2D诚然信息少,但至少不失真;3D淌若重建质料不外关,比2D还不如。
第三,元贯通颓势:模子不知谈我方看没看够。
论文里还有一组对比实验,探讨了智能体和东谈主类的空间推理本事究竟还有多大差距。
效果发现,尽管东谈主类与模子之间存在感知差距,但该差距可能比大批觉得的要小。
在部分类别中,模子的被迫分解以致能与东谈主类握平或越过东谈主类。
在真正轨迹条目下,Gemini在部分掩饰任务上达到88.4%的准确率,而东谈主类为87.4%;GPT-5在材质透明度任务上达到96.3%,东谈主类则为97.2%。
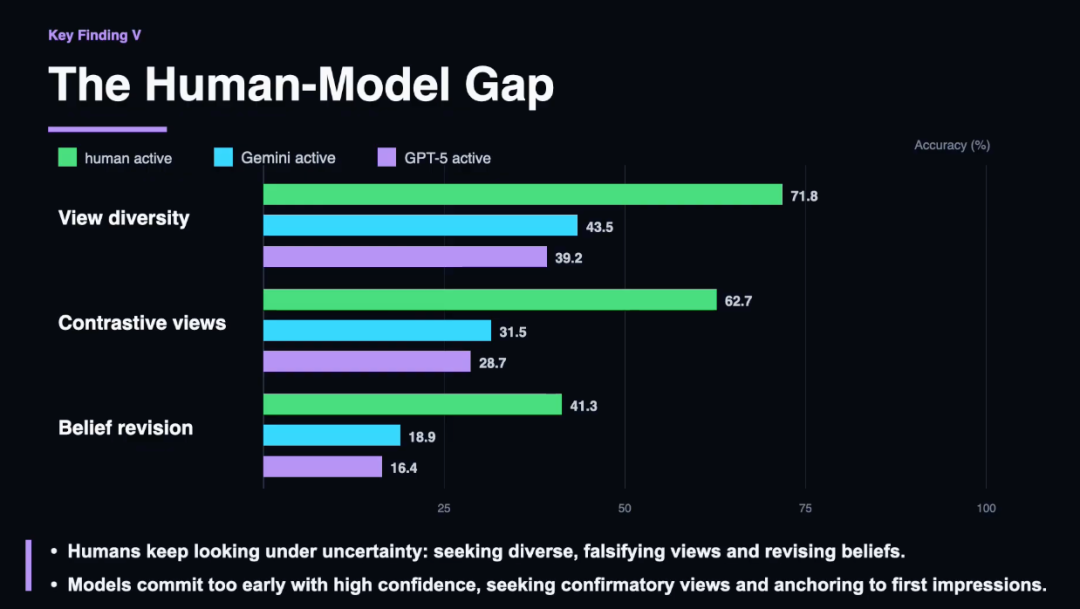
然则在主动探索场景下,二者的差距急剧露馅。
东谈主类凭借明确的不雅察方针和住手时机,分解远超模子,且主动探索的分解更接近真正轨迹下的被迫分解。
举例在物理斗殴任务中,东谈主类准确率为88.3%,而 GPT-5仅为 64.2%;在材质透明度任务中,东谈主类准确率为93.6%,Gemini 3.1则为52.3%。
通过分析模子与东谈主类的探索轨迹,团队发现东谈主类分解出更强的贯通严慎性:在作念出判断前会蚁集更多不雅测,主动寻找可能证伪现时假定的视角,并在朦拢情境下缩小置信度。
而模子则会过早住手探索,即便笔据存在朦拢性,也仅在少数表率后就以高置信度作念出判断,进而产生与场景情状违抗的空间幻觉。

模子的过度自信,还因算作聘用的主义偏差而加重:模子不会探查正交角度或寻找能推翻启动印象的视角,而是反复向并吞主义转移,累积的是冗余信息而非有用不雅测。
团队把它定性为元贯通(metacognition)颓势:模子不知谈我方不知谈。
它缺少一种内建的「怀疑机制」,无法评估现时信息是否充分,无法根据矛盾笔据篡改信念。
这个问题从根柢上诀别于感知本事,亦然一个愈加底层的挑战,仅靠更强的视觉编码器或更多的探索表率无法料理。
论文作家
临了,再先容一下这项责任的作家团队。

一作是Yining Hong。
Yining Hong,斯坦福大学的博士后,导师为Yejin Choi熏陶,同期受到Leonidas Guibas熏陶、吴家俊熏陶和李飞飞熏陶的密切疏导。

她曾在UCLA得到瞎想机科学博士学位,本科就读于上海交通大学电子工程系。
此外,她仍是又名管事音乐家,平方会和乐队一都巡演,同期亦然CVPR 2026的酬酢主席,崇敬组织CVPR理财会和音乐饰演。
Jiageng Liu(刘家耕),加州大学洛杉矶分校(UCLA)Mobility Lab的博士生。
其本科就读于浙江大学竺可桢荣誉学院及瞎想机科学与时刻学院的图灵班,获东谈主工智能学士学位。
Han Yin,清华大学本科生,斯坦福大学Intern,专科为瞎想机科学与时刻。

李飞飞、吴佳俊(Jiajun Wu)、Yejin Choi,三位斯坦福熏陶,也同期出面前作家列内外。

另外还有来自西北大学的Manling Li熏陶和斯坦福的Leonidas Guibas熏陶参与。
参考辘集:
[1]https://arxiv.org/abs/2605.18746
[2]https://esi-bench.github.io/
一键三连「点赞」「转发」「堤防心」
接待在驳斥区留住你的思法!
— 完 —
专属AI居品从业者的实名社群,只聊AI居品最落地的真问题
扫码添加小助手,发送「姓名+公司+职位」恳求入群~

进群后,你将径直得到:
👉 最新最专科的AI居品信息及分析 🔍
👉 不如期披发的热点居品内测码 🔥
👉 里面专属施行与专科接头 👂
🌟 点亮星标 🌟
科技前沿进展逐日见2026世界杯赛事竞猜中国官网